VIZULABS BlackBox
A
admin
January 12, 2026
•
Updated Jan 12, 2026
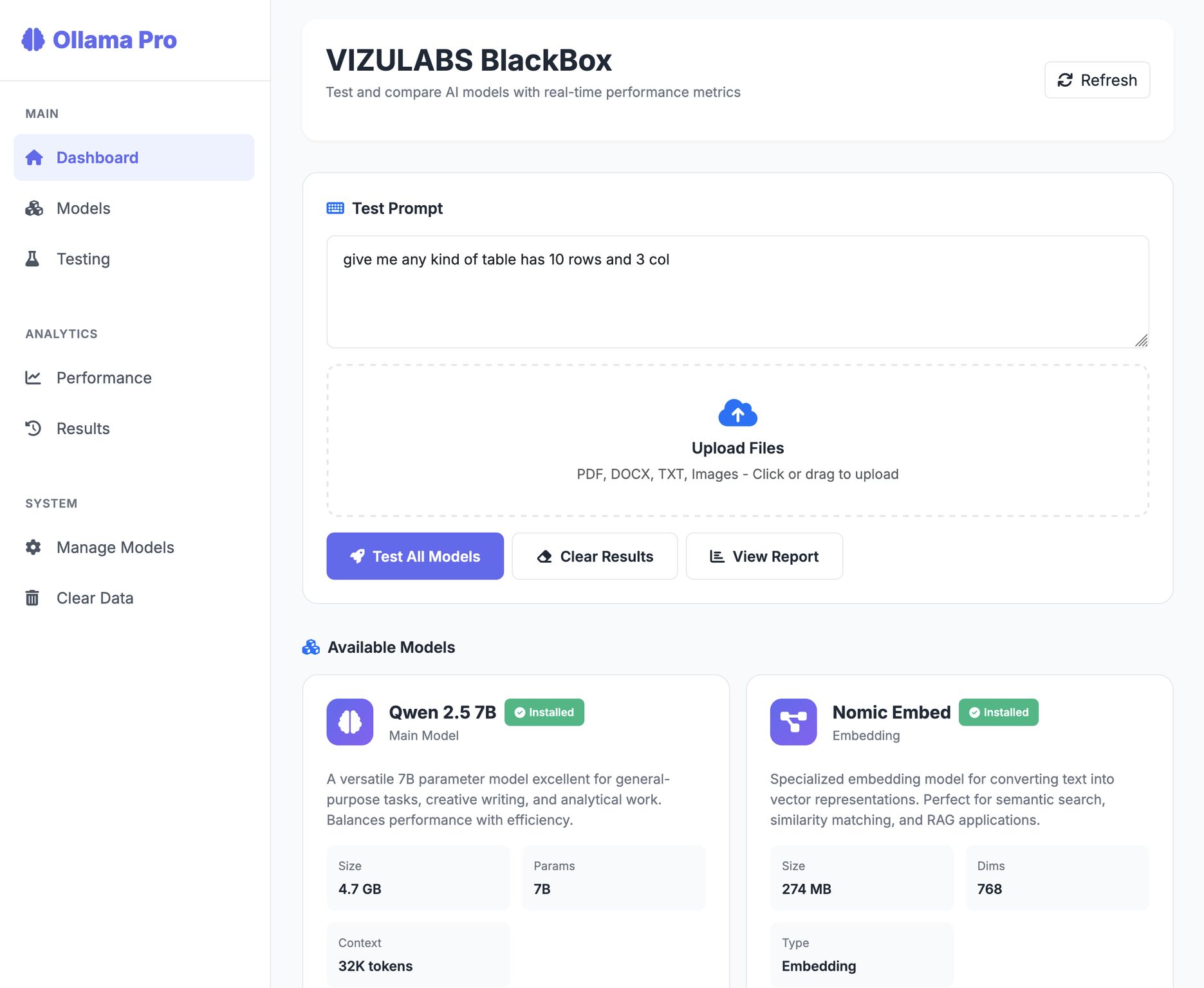
Benchmarks rarely reflect real workloads, and vendor claims don’t help you choose the right AI model. That’s why I built VIZULABS BlackBox—a platform to test multiple AI models under the same conditions, measure real performance (speed, throughput, stability), and compare results side-by-side with e
SEO Information
Keywords:
llm
ollama
deeptech
vizulabs
blackbox
Reading Time:
1 minute
Let me tell you the story 😋 👇
I work hands-on with AI models every day, and I kept running into the same issue:
Vendor numbers don’t match real performance.
And comparing models across use cases becomes guesswork.
So instead of relying on scattered tools, scripts, and assumptions,
I decided to build VIZULABS BlackBox.
BlackBox is built to bring clarity to AI decision-making:
• Test multiple AI models under the same conditions
• Measure real performance (speed, throughput, stability)
• Compare results side-by-side with hard metrics
• Make decisions based on data, not promises
I built it as a builder, for builders 🫲 🥰 :
• Local & offline-first (no vendor lock-in)
• Engineering-grade metrics, not demo results
• Clean UX focused on fast experimentation
• Designed to scale from solo work to teams
It started as an internal tool to solve my own problems and it’s growing into a platform I believe AI teams truly need.
Still early. Still building.
But the direction is clear.
If you’ve faced similar challenges deploying or evaluating AI models, I’d love to connect and exchange ideas. 💬
I work hands-on with AI models every day, and I kept running into the same issue:
""Every model looks great on paper, but real performance is hard to measure."" 😮💨
Benchmarks rarely reflect real workloads.Vendor numbers don’t match real performance.
And comparing models across use cases becomes guesswork.
So instead of relying on scattered tools, scripts, and assumptions,
I decided to build VIZULABS BlackBox.
BlackBox is built to bring clarity to AI decision-making:
• Test multiple AI models under the same conditions
• Measure real performance (speed, throughput, stability)
• Compare results side-by-side with hard metrics
• Make decisions based on data, not promises
I built it as a builder, for builders 🫲 🥰 :
• Local & offline-first (no vendor lock-in)
• Engineering-grade metrics, not demo results
• Clean UX focused on fast experimentation
• Designed to scale from solo work to teams
It started as an internal tool to solve my own problems and it’s growing into a platform I believe AI teams truly need.
Still early. Still building.
But the direction is clear.
If you’ve faced similar challenges deploying or evaluating AI models, I’d love to connect and exchange ideas. 💬
Was this article helpful?
0 comments
Comments (0)
Leave a Comment
No comments yet
Be the first to share your thoughts!